
Создание кластеризованных и некластеризованных индексов в SQL Server
В SQL Server существуют два типа индексов; Кластерные и некластерные индексы. Как кластеризованные, так и некластеризованные индексы имеют одинаковую физическую структуру. Более того, оба они хранятся в SQL Server как структура B-Tree.
Кластерный индекс:
Кластерный список – это особый тип индекса, который перестраивает физическое хранилище записей в таблице. В SQL Server индексы используются для ускорения операций с базой данных, что приводит к высокой производительности. Следовательно, таблица может иметь только один кластерный индекс, который обычно выполняется для первичного ключа. Конечные узлы кластерного индекса содержат «страницы данных». Таблица может иметь только один кластерный индекс.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Давайте создадим кластерный индекс для лучшего понимания. Прежде всего, нам нужно создать базу данных.
Создание базы данных
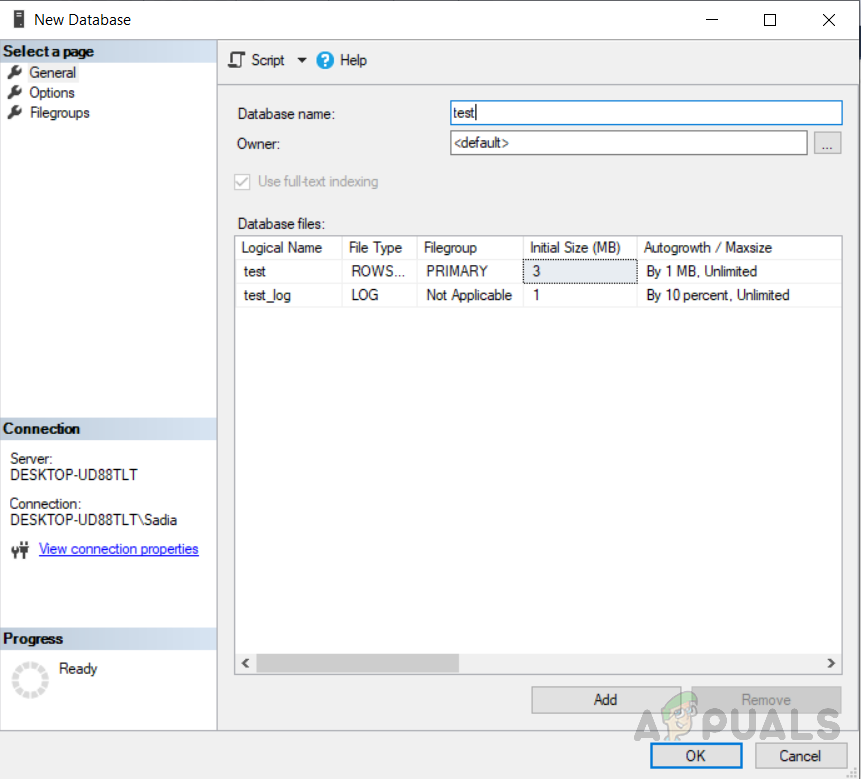
Для того, чтобы создать базу данных. Щелкните правой кнопкой мыши на «Базы данных» в проводнике объектов и выберите «Новая база данных». Введите имя базы данных и нажмите ОК. База данных была создана, как показано на рисунке ниже.
 Создание таблицы с использованием представления дизайна
Создание таблицы с использованием представления дизайна
Теперь мы создадим таблицу с именем «Сотрудник» с первичным ключом, используя представление конструктора. На рисунке ниже мы видим, что мы в первую очередь присвоили поле с именем «ID», и мы не создали никакого индекса в таблице.
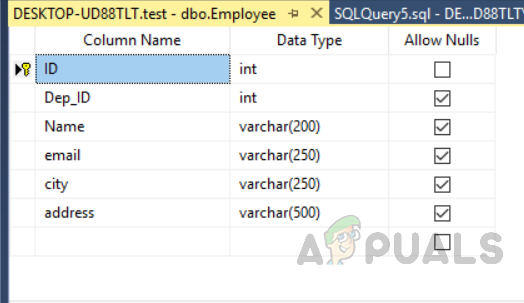 Создание таблицы с именем «Сотрудник» с ID в качестве первичного ключа
Создание таблицы с именем «Сотрудник» с ID в качестве первичного ключа
Вы также можете создать таблицу, выполнив следующий код.
ИСПОЛЬЗОВАНИЕ [test]
ИДТИ
SET ANSI_NULLS ON
ИДТИ
SET QUOTED_IDENTIFIER ON
ИДТИ
СОЗДАТЬ СТОЛ [dbo],[Employee](
[ID] [int] IDENTITY (1,1) НЕ NULL,
[Dep_ID] [int] ЗНАЧЕНИЕ NULL,
[Name] [varchar](200) NULL,
[email] [varchar](250) NULL,
[city] [varchar](250) NULL,
[address] [varchar](500) NULL,
CONSTRAINT [Primary_Key_ID] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕР
(
[ID] ASC
) С (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ВКЛ [PRIMARY]
ИДТИ
Вывод будет следующим.
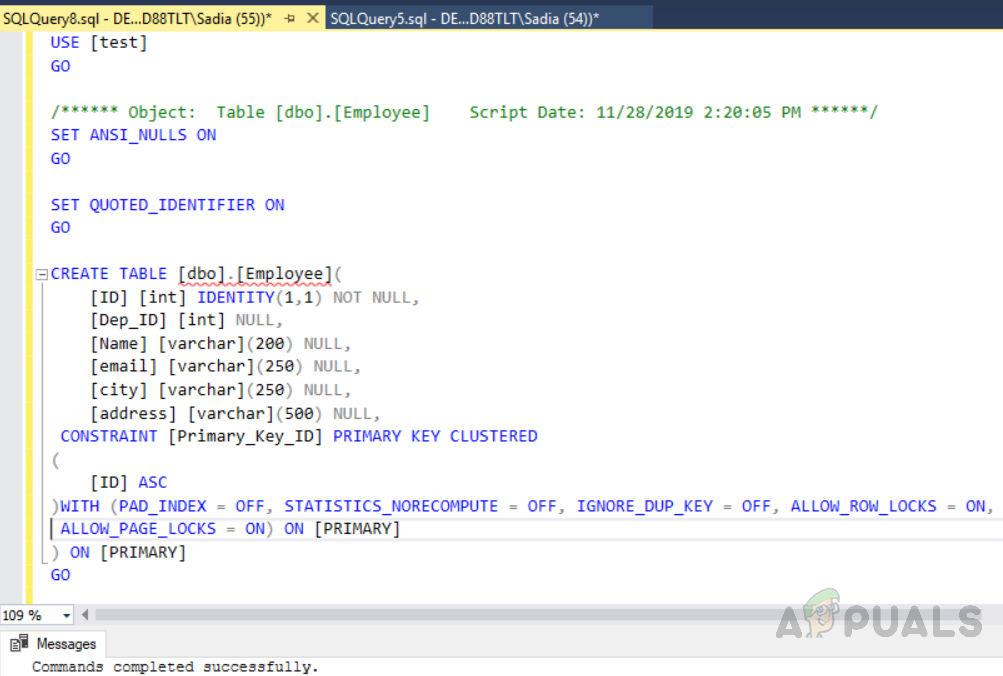 Создание таблицы с именем «Сотрудник» с ID в качестве первичного ключа
Создание таблицы с именем «Сотрудник» с ID в качестве первичного ключа
Приведенный выше код создал таблицу с именем «Сотрудник» с идентификатором поля, уникальный идентификатор в качестве первичного ключа. Теперь в этой таблице кластерный индекс будет автоматически создан для идентификатора столбца из-за ограничений первичного ключа. Если вы хотите увидеть все индексы в таблице, запустите хранимую процедуру sp_helpindex. Выполните следующий код, чтобы увидеть все индексы в таблице с именем «Сотрудник». Эта процедура хранения принимает имя таблицы в качестве входного параметра.
ИСПОЛЬЗОВАНИЕ теста
EXECUTE sp_helpindex Сотрудник
Вывод будет следующим.
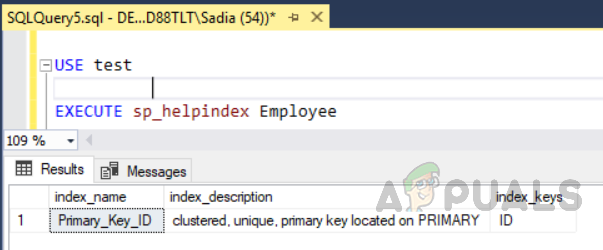 «Sp_helpindex» покажет все индексы в таблице сотрудников.
«Sp_helpindex» покажет все индексы в таблице сотрудников.
Другой способ просмотра табличных индексов – перейти к «таблицам» в проводнике объектов. Выберите таблицу и расходуйте ее. В папке indexes вы можете увидеть все индексы, относящиеся к этой конкретной таблице, как показано на рисунке ниже.
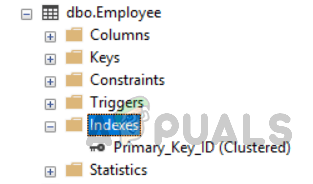 Просмотр всех индексов в таблице
Просмотр всех индексов в таблице
Поскольку это кластерный индекс, логический и физический порядок индекса будет одинаковым. Это означает, что если запись имеет идентификатор 3, то она будет сохранена в третьей строке таблицы. Аналогично, если пятая запись имеет идентификатор 6, она будет сохранена в 5-м месте таблицы. Чтобы понять порядок записей, вам необходимо выполнить следующий скрипт.
ИСПОЛЬЗОВАНИЕ [test]
ИДТИ
SET IDENTITY_INSERT [dbo],[Employee] НА
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (8, 6, N’Humbaerto Acevedo ‘, N’humbaerto.acevedo@gmail.com’, N’SINT PAUL ‘, N’895 E 7-й Сент-Пол-Мэн, 551063852’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (9, 6, N’Humbaerto Acevedo ‘, N’humbaerto.acevedo@gmail.com’, N’SAINT PAUL ‘, N’895 E 7-й Сент-Пол-Мэн, 551063852’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]ЦЕННОСТИ (10, 7, N’Pilar Ackaerman ‘, N’pilar.ackaerman@gmail.com’, N’ATLANTA ‘, N’5813 Eastern Ave Hyattsville Md 207822201’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (11, 1, N’Aaaronboy Gutierrez, N’aronboy.gutierrez@gmail.com ‘, N’HILLSBORO’, N’5840 Ne Cornell Rd Hillsboro Or 97124 ‘)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (12, 2, N’Aabdi Maghsoudi ‘, N’abdi_maghsoudi@gmail.com’, N’BRENTWOOD ‘, N’987400 Небрасский медицинский центр, Омаха, Ne 681987400’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (13, 3, N’Aabharana, Sahni ‘, N’abharana.sahni@gmail.com’, N’HYATTSVILLE ‘, N’2 Barlo Circle Suite A Dillsburg Pa 170191’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (14, 3, N’Aabharana, Sahni ‘, N’abharana.sahni@gmail.com’, N’HYATTSVILLE ‘, N’2 Barlo Circle Suite A Dillsburg Pa 170191’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (1, 1, N’Aaaronboy Gutierrez ‘, N’aronboy.gutierrez@gmail.com’, N’HILLSBORO ‘, N’5840 Ne Cornell Rd Hillsboro Or 97124’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (2, 2, N’Aabdi Maghsoudi ‘, N’abdi_maghsoudi@gmail.com’, N’BRENTWOOD ‘, N’987400 Небрасский медицинский центр, Омаха, Ne 681987400’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (3, 3, N’Aabharana, Sahni ‘, N’abharana.sahni@gmail.com’, N’HYATTSVILLE ‘, N’2 Barlo Circle Suite A Dillsburg Pa 170191’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (4, 3, N’Aabharana, Sahni ‘, N’abharana.sahni@gmail.com’, N’HYATTSVILLE ‘, N’2 Barlo Circle Suite A Dillsburg Pa 170191’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (5, 4, N’Aabish Mughal, N’abish_mughal@gmail.com, N’OMAHA, N’2975 Crouse Lane Burlington Nc 272150000 ‘)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (6, 5, N’Aabram Howell ‘, N’aronboy.gutierrez@gmail.com’, N’DILLSBURG ‘, N’868 York Ave Atlanta Ga 303102750’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (7, 5, N’Aabram Howell ‘, N’aronboy.gutierrez@gmail.com’, N’DILLSBURG ‘, N’868 York Ave Atlanta Ga 303102750’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (15, 4, N’Aabish Mughal ‘, N’abish_mughal@gmail.com’, N’OMAHA ‘, N’2975 Crouse Lane Burlington Nc 272150000’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (16, 5, N’Aabram Howell ‘, N’aronboy.gutierrez@gmail.com’, N’DILLSBURG ‘, N’868 York Ave Atlanta Ga 303102750’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (17, 5, N’Aabram Howell ‘, N’aronboy.gutierrez@gmail.com’, N’DILLSBURG ‘, N’868 York Ave Atlanta Ga 303102750’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (18, 6, N’Humbaerto Acevedo ‘, N’humbaerto.acevedo@gmail.com’, N’SINT PAUL ‘, N’895 E 7-й Сент-Пол-Мэн, 551063852’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) ЦЕННОСТИ (19, 6, N’Humbaerto Acevedo ‘, N’humbaerto.acevedo@gmail.com’, N’SAINT PAUL ‘, N’895 E 7-й Сент-Пол, Mn 551063852’)
ВСТАВИТЬ [dbo],[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]ЦЕННОСТИ (20, 7, N’Pilar Ackaerman ‘, N’pilar.ackaerman@gmail.com’, N’ATLANTA ‘, N’5813 Eastern Ave Hyattsville Md 207822201’)
SET IDENTITY_INSERT [dbo],[Employee] OFF
Хотя записи хранятся в столбце «Id» в случайном порядке значений. Но из-за кластеризованного индекса в столбце id. Записи физически хранятся в порядке возрастания значений в столбце id. Чтобы убедиться в этом, нам нужно выполнить следующий код.
Выберите * из test.dbo.Employee
Вывод будет следующим.
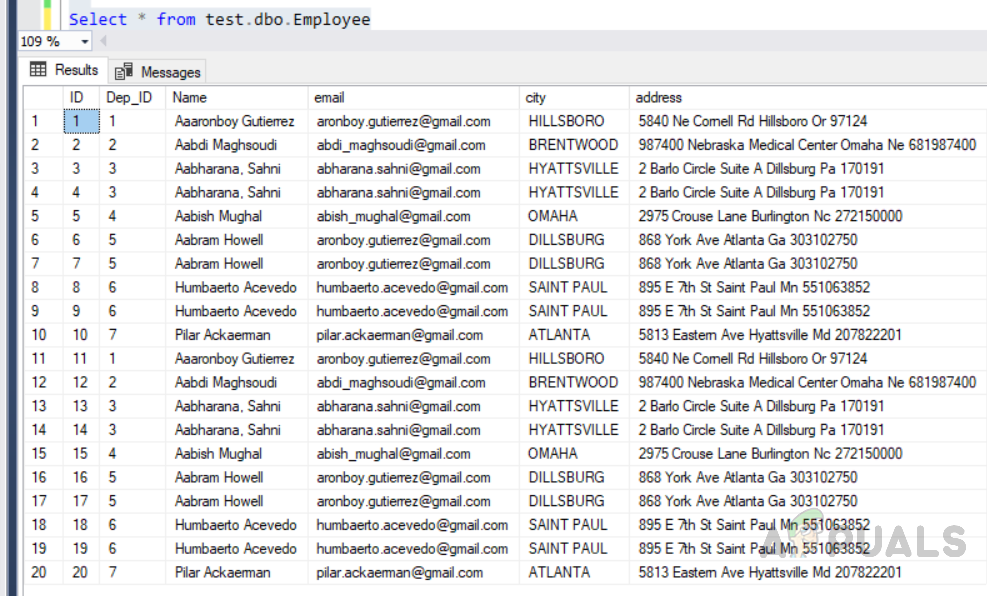 Выбор всех записей из таблицы Employee. Записи показываются в порядке возрастания столбца ID
Выбор всех записей из таблицы Employee. Записи показываются в порядке возрастания столбца ID
Как видно из приведенного выше рисунка, записи были получены в порядке возрастания значений в столбце id.
Индивидуальный кластерный индекс
Вы также можете создать собственный кластерный индекс. Поскольку мы можем создать только один кластерный индекс, нам нужно удалить предыдущий. Чтобы удалить индекс, выполните следующий код.
ИСПОЛЬЗОВАНИЕ [test]
ИДТИ
ALTER TABLE [dbo],[Employee] DROP CONSTRAINT [Primary_Key_ID] С (ОНЛАЙН = ВЫКЛ)
ИДТИ
Вывод будет следующим.
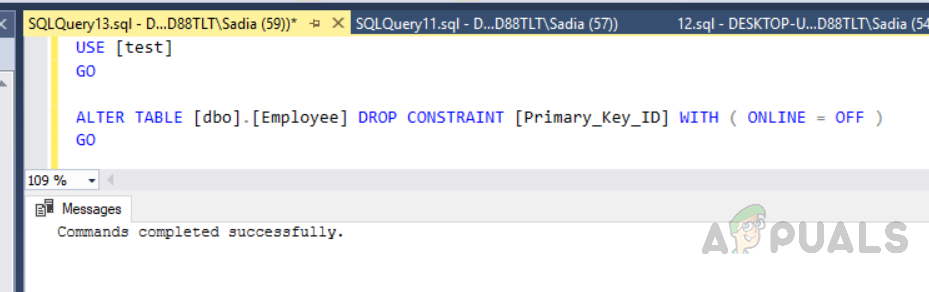 Удаление уже созданного индекса на столе
Удаление уже созданного индекса на столе
Теперь для создания индекса выполните следующий код в окне запроса. Этот индекс был создан для нескольких столбцов, поэтому он называется составным индексом.
ИСПОЛЬЗОВАНИЕ [test]
ИДТИ
СОЗДАТЬ КЛАСТЕРНЫЙ ИНДЕКС [ClusteredIndex-20191128-173307] НА [dbo],[Employee]
(
[ID] ASC,
[Dep_ID] ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
ИДТИ
Выход будет следующим
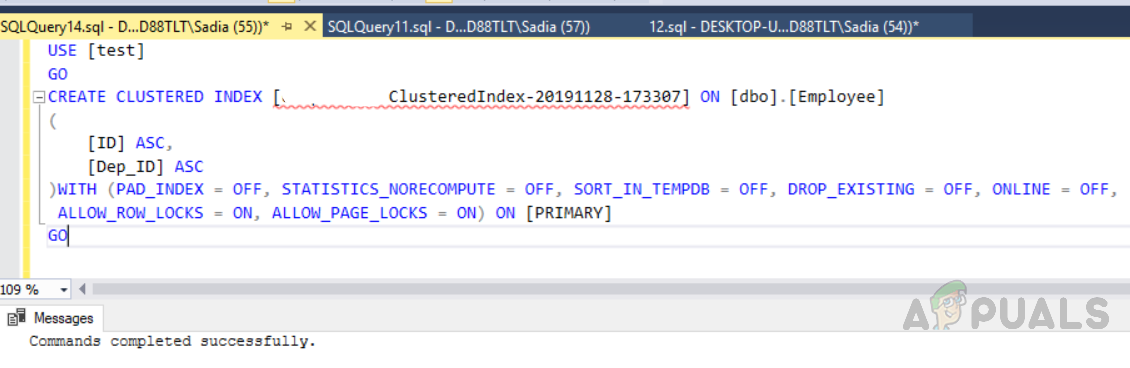 Создание пользовательского индекса для таблицы с именем Employee
Создание пользовательского индекса для таблицы с именем Employee
Мы создали пользовательский кластерный индекс по ID и Dep_ID. Это отсортирует строки по Id, а затем по Dep_Id. Для просмотра выполните следующий код. Результат будет в порядке возрастания идентификатора, а затем по Dep_id.
ВЫБРАТЬ [ID] ,[Dep_ID],[Name],[email] ,[city] ,[address] ОТ [test],[dbo],[Employee]
Вывод будет следующим.
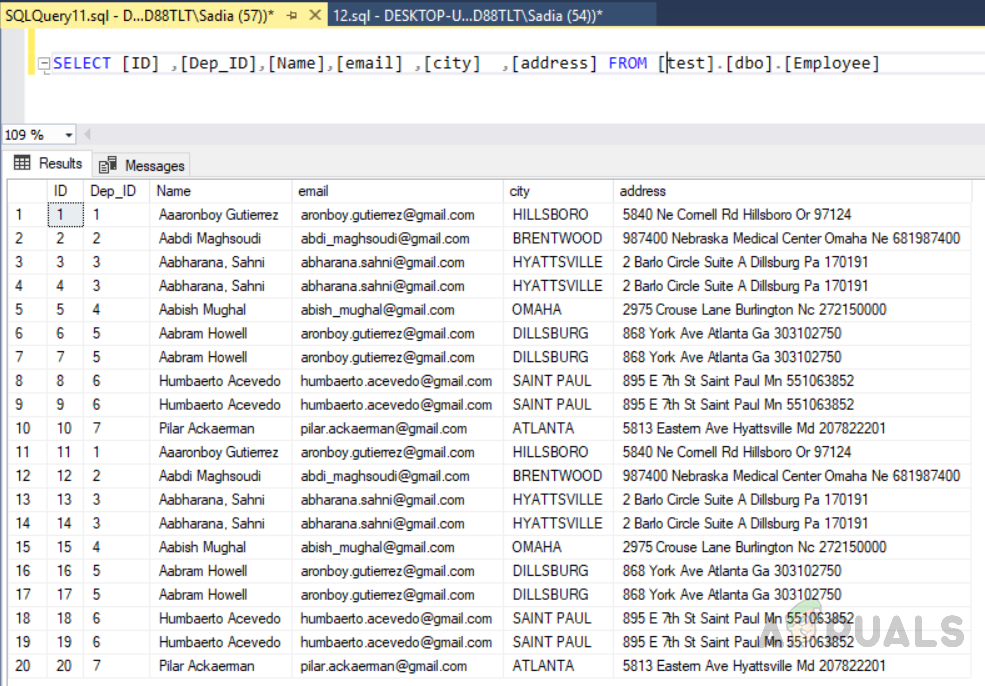 Пользовательский кластерный индекс сортирует строки по Id, а затем по Dep_Id в соответствии с его определением.
Пользовательский кластерный индекс сортирует строки по Id, а затем по Dep_Id в соответствии с его определением.
Некластеризованный индекс:
Некластеризованный индекс – это особый тип индекса, в котором логический порядок индекса не совпадает с физическим порядком строк, хранящихся на диске. Конечный узел некластеризованного индекса не содержит страниц данных, а содержит информацию о строках индекса. Таблица может содержать до 249 индексов. По умолчанию ограничение уникального ключа создает некластеризованный индекс. В операции чтения некластеризованные индексы работают медленнее, чем кластеризованные индексы. Некластеризованный индекс содержит копию данных из проиндексированных столбцов, сохраненных в порядке, а также ссылки на фактические строки данных; указатели на кластерный список, если таковые имеются. Поэтому рекомендуется выбирать только те столбцы, которые используются в индексе, вместо использования *. Таким образом, данные могут быть получены непосредственно из дублирующего индекса. В противном случае кластерный индекс также используется для выбора оставшихся столбцов, если он создан.
Синтаксис, используемый для создания некластеризованного индекса, аналогичен кластерному индексу. Однако ключевое слово «NONCLUSTERED» используется вместо «CLUSTERED» в случае некластеризованного индекса. Выполните следующий сценарий для создания некластеризованного индекса.
ИСПОЛЬЗОВАНИЕ [test]
ИДТИ
SET ANSI_PADDING ON
ИДТИ
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС [NonClusteredIndex-20191129-104230] НА [dbo],[Employee]
(
[Name] ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
ИДТИ
Вывод будет следующим.
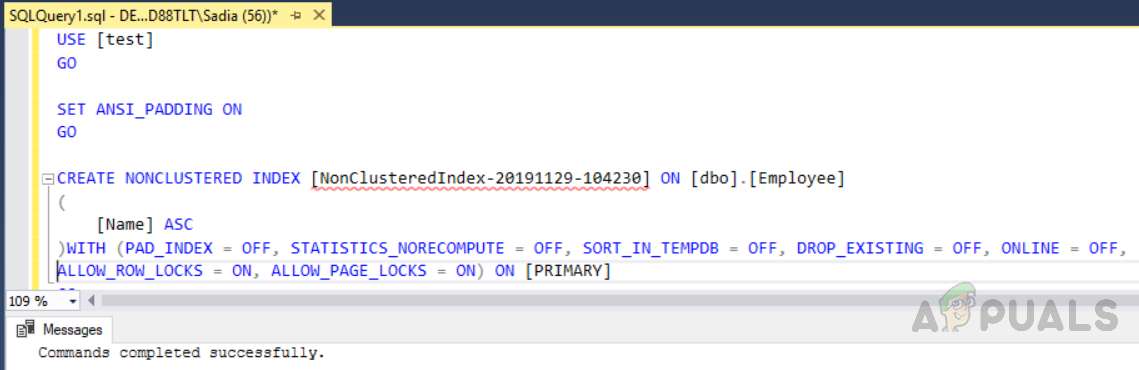 Создание некластеризованного индекса для таблицы с именем «Сотрудник»
Создание некластеризованного индекса для таблицы с именем «Сотрудник»
Записи таблицы сортируются по кластерному индексу, если он был создан. Этот новый некластеризованный индекс отсортирует таблицу в соответствии с ее определением и будет храниться в отдельном физическом адресе. Приведенный выше скрипт создаст индекс для столбца «NAME» таблицы Employee. Этот индекс будет сортировать таблицу в порядке возрастания столбца «Имя». Данные таблицы и индекс будут храниться в разных местах, как мы уже говорили ранее. Теперь выполните следующий скрипт для просмотра влияния нового некластеризованного индекса.
выберите имя от сотрудника
Вывод будет следующим.
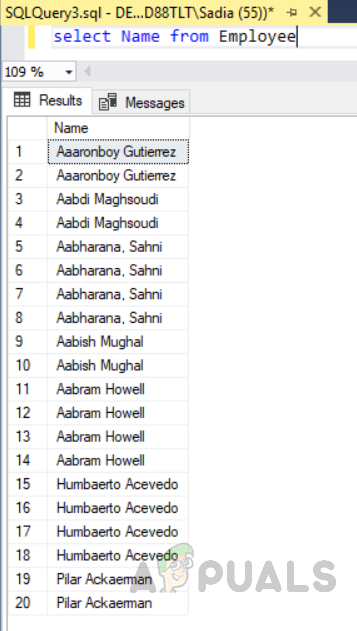 По определению некластеризованного индекса в таблице «Сотрудник» он будет сортировать столбец «Имя» в порядке возрастания при выборе имени из таблицы.
По определению некластеризованного индекса в таблице «Сотрудник» он будет сортировать столбец «Имя» в порядке возрастания при выборе имени из таблицы.
На рисунке выше видно, что столбец «Имя» таблицы «Сотрудник» показан в порядке возрастания столбца «имя», хотя мы не упомянули предложение «Упорядочить по ASC» в предложении выбора. Это происходит из-за некластеризованного индекса в столбце «Имя», созданного в таблице «Сотрудник». Теперь, если запрос написан для получения имени, электронной почты, города и адреса конкретного человека. База данных сначала будет искать это конкретное имя в индексе, а затем извлекать соответствующие данные, что уменьшит время выборки запроса, особенно когда данные огромны.
выберите имя, адрес электронной почты, город, адрес сотрудника, где имя = ‘Aaaronboy Гутьеррес’
Заключение
Из приведенного выше обсуждения мы узнали, что кластеризованный индекс может быть только один, тогда как некластеризованный индекс может быть много. Кластерный индекс быстрее по сравнению с некластеризованным индексом. Кластерный индекс не использует дополнительное пространство для хранения, тогда как некластеризованному индексу требуется дополнительная память для их хранения. Если мы применяем ограничение первичного ключа к таблице, автоматически создается кластеризованный индекс. Более того, если мы применяем ограничение уникального ключа к любому столбцу, для него автоматически создается некластеризованный индекс. Некластеризованный индекс быстрее по сравнению с кластеризованным индексом для операций вставки и обновления. Таблица может не иметь некластеризованного индекса.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)